R for data science笔记0.1 introduction
简介
数据科学是一个令人兴奋的学科,它允许你用你的知识理解来转化数据。本书的目标是帮助您学习R中最重要的工具,使您能够进行数据科学工作。阅读本书后,您将拥有使用R的最佳部分来处理各种数据科学挑战的工具。
你将学到什么?
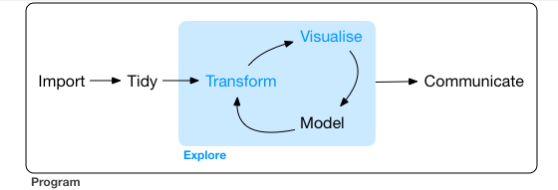
数据科学是一个巨大的领域,没有办法通过阅读一本书来掌握它。本书的目标是为您提供最重要工具的坚实基础。我们在典型的数据科学项目中所需的工具模型如下所示:

首先,您必须将数据导入到R中。这通常意味着您将数据存储在文件,数据库或Web API中,并将其加载到R中的数据框中。
导入数据后要整理。整理数据意味着把数据集的语义与存储方式相匹配。简而言之,当您的数据整理时,每列都是一个变量,每行都是一个值。整洁的数据是重要的,因为一致的结构可以让您集中精力处理有关数据的问题,而不是用于将数据转换为用于实现不同功能的正确形式。
一旦你有整洁的数据,一个常见的第一步是转换它。转换包括缩小感兴趣的观察范围(像缩小为一个城市、一个年份),用已有变量的函数创建新变量(如速度和时间的计算速度),计算一组汇总统值(如计数或均值)。整理和转换合在一起被称为wrangling(争吵?),因为将数据转换成一种自然的形式通常感觉就像一场战斗!
可视化(数据的发现):一个很好的可视化将会显示你没有想到的内容,或提出有关数据的新问题。一个好的可视化也可能暗示你的错误,或者暗示你需要收集不同的数据。可视化可能会让你感到惊讶,但扩展性不是特别好,因为它们需要人类来解释。
模型(数据的解释)是可视化的补充工具。一旦你提出了足够的精确问题,你可以使用模型来回答。模型是一个基本的数学或计算工具,因此它们通常扩展的很好。但是每个模型都会做出假设,而且就其本质而言,模型不能质疑自己的假设。这意味着一个模型不能从根本上让你感到惊讶。
数据科学的最后一步是沟通,这是任何数据分析项目都绝对重要的一部分。你的模型和可视化如何引导你理解数据并不重要,除非你要与他人交流你的结果。
围绕所有这些工具是编程。编程是一个工具,您可以在项目的每个部分使用。要成为一名数据科学家,你不需要成为一名专业程序员,但学习更多关于编程的知识
带来回报,因为这会让你变得更好地自动化解决常见任务,并更轻松地解决新问题。
你将在每个数据科学项目中使用这些工具,但对于大多数项目来说,它们还不够。这里有一个大致的80/20规则:使用本书中介绍的工具,你可以解决每个项目中80%的问题,但剩下的20%需要其他工具。在本书中,我们会向你提供一些资源,你可以从中了解更多信息。
这本书的结构
之前的工具书中,面对数据科学工具的教程大致是按照在分析中使用它们的顺序来组织的。然而,根据我们的经验,先学习数据导入和整理并不是最佳选择,因为在80%的情况下,它是常规和无聊的,而在另外20%的情况下,它是怪异和令人沮丧的。那可不是开始学习新学科的好地方!
相反,我们将从已经导入并整理过的数据的可视化和转换开始。这样,当你采集和整理自己的数据时,你的积极性将保持很高,因为你知道痛苦是值得的。在每一章中,我们都试图坚持一种一致的模式:从一些激励人的例子开始,这样你可以看到全局,然后再深入细节。本书的每一部分都配有练习,帮助你练习所学到的知识。虽然跳过练习很诱人,但没有比练习实际问题更好的学习方法了。
你会学到什么
有几个重要的话题本书没有涉及。我们相信,重要的是要坚持不懈地专注于最重要的事情,这样你就可以尽快振作起来。这意味着本书不可能涵盖所有重要的主题。
建模
建模对于数据科学来说超级重要,不幸的是,我们在这里没有足够的篇幅来介绍它。要了解更多关于建模的知识,我们强烈推荐我们的同事Max Kuhn和Julia Silge的Tidy modeling with R。本书将教你tidymodels包,你可以从它的名字猜到,它与本书中使用的tidyverse包有很多关联。
大数据
本书主要关注内存中的小型数据集。这是一个正确的起点,因为除非你有处理小数据的经验,否则你无法处理大数据。本书主要部分将介绍的工具可以轻松处理数百兆的数据,只要稍加注意,通常也可以处理几Gb的数据。我们还会介绍如何从database和parquet文件中获取数据,这两种文件都经常用于存储大数据。你不一定能够处理整个数据集,但这不是问题,因为你只需要一个子集或子样本就可以回答你感兴趣的问题。
Python, Julia, 和朋友们
在本书中,你不会学到任何关于Python、Julia或其他对数据科学有用的编程语言的知识。这并不是因为我们认为这些工具不好,不是的!在实践中,大多数数据科学团队使用混合语言,通常至少是R和Python。但我们坚信一次最好掌握一种工具,R就是一个很好的起点。
准备你的行囊
为了更好地理解本书,我们对你已经掌握的知识做了一些假设。一般来说,你应该精通数字,如果你已经有了一些基本的编程经验,这将很有帮助。如果你从未编程过,Garrett写的Hands on Programming with R是本书很有价值的附书。要运行本书中的代码,你需要四样东西:
R、RStudio、名为tidyverse的R包,以及其他几个包。
包是可复制R代码的基本单位。它们包括可重复使用的函数、描述如何使用它们的文档和示例数据。
下载R和RStudio
https://posit.co/download/rstudio-desktop/
下载tidyverse
你还需要安装一些R包。在本书中,你将学习到的大多数包都是tidyverse的一部分。
你可以使用一行代码安装完整的tidyverse:
1 | install.packages("tidyverse") |
在控制台中输入这行代码,然后按回车运行。R会从CRAN下载这些包并安装到你的计算机上。
只有用library()加载包,才能使用包中的函数、对象或帮助文件。安装包后,可以使用library()函数加载它:
1 | library(tidyverse) |
这告诉你tidyverse加载了9个包:dplyr、forcats、ggplot2、lubridate、purrr、readr、stringr、tibble、tidyr。这些被认为是tidyverse的核心,因为你将在几乎所有的分析中使用它们。tidyverse中的包变化相当频繁。你可以通过运行tidyverse update()来查看更新是否可用。
其他包
还有许多其他优秀的软件包并不属于tidyverse,因为它们解决的是不同领域的问题,或者使用不同的底层原理。换句话说,对tidyverse的补充不是messverse,而是manyverse。在本书中,我们将使用许多tidyverse之外的包。例如,我们将使用以下包,因为它们为我们在学习R的过程中提供了有趣的数据集:
1 | install.packages( |
我们还将使用其他一些包作为示例数据。你现在不需要安装它们,只要记住当你看到这样的错误时:
1 | library(ggrepel) |
记得使用install.packages("ggrepel")来安装包即可。
运行R代码
在本书中,引用代码时使用了一套一致的约定:
- 使用代码字体显示函数,后面跟着一对括号,如
sum()或mean()。 - 其他R对象,如数据或函数参数,使用代码字体,没有括号,如
flights或x。 - 有时,为了清楚地表明对象来自哪个包,我们会在包名后加上两个冒号,如
dplyr::mutate()或nycflights13::flights。这也是有效的R代码。




