本教程描述了为raw对象添加注释,并介绍了之后的数据处理中这些注释可以被有什么用。
我们先导入数据:
1 | import os |
Reading 0 … 36037 = 0.000 … 60.000 secs…
MNE-Python中的注释(annotation)是一种存储关于Raw对象时长信息的短字符串的方式。annotation是类似列表的对象,其中每个元素包含三段信息:开始时间(以秒为单位)、持续时间(以秒为单位)和描述(文本字符串)。此外,Annotations对象本身还跟踪orig_time,这是一个POSIX时间戳,表示应该解释注释开始的相对真实时间。
创建注释对象
如果您事先了解到您想要注释的raw对象的时长,可以通过编程方式创建注释,您甚至可以将列表或数组传递给注释,同时注释多个时间段:
1 | my_annot = mne.Annotations( |
<Annotations | 3 segments: AAA (1), BBB (1), CCC (1)>
注意orig_time是None的,因为我们没有指定。在这些情况下,当您将注释添加到raw对象时,orig_time会匹配记录的第一个时间样本,因此orig_time将被设置为匹配记录测量日期raw.info['meas_data']。
1 | raw.set_annotations(my_annot) |
<Annotations | 3 segments: AAA (1), BBB (1), CCC (1)>
True
由于示例数据来自Neuromag系统,该系统在记录开始之前开始计数时间样本,所以将my_annot添加到raw对象还涉及另一个更改(这个更改时自动的):等于第一个被记录的样本的时间的偏移量(raw.first_samp / raw.info['sfreq'])要被添加到每个注释的onset值中:
1 | time_of_first_sample = raw.first_samp / raw.info["sfreq"] |
[45.95597083 47.95597083 49.95597083]
[45.95597083 47.95597083 49.95597083]
如果你知道注释的开始时间是相对于其他时间的,你可以在调用set_annotations()之前设置orig_time,开始时间将根据指定的orig_time和raw.info['meas_date']之间的时间差进行调整,但不需要对raw.first_samp进行额外的调整。可以用各种方式指定orig_time,这里我们将使用ISO 8601格式的字符串,并将其设置为比raw.info['meas_date']晚50秒。
1 | time_format = "%Y-%m-%d %H:%M:%S.%f" |
2002-12-03 19:02:00.720100
[3. 5. 7.]
[53. 55. 57.]
如果您的注释超出了Raw对象中的数据时间范围,则数据范围之外的注释将不会添加到Raw,并将发出警告。
现在你的注释已经被添加到Raw对象中,当你可视化Raw对象时,你可以看到它们:
1 | fig = raw.plot(start=2, duration=6) |
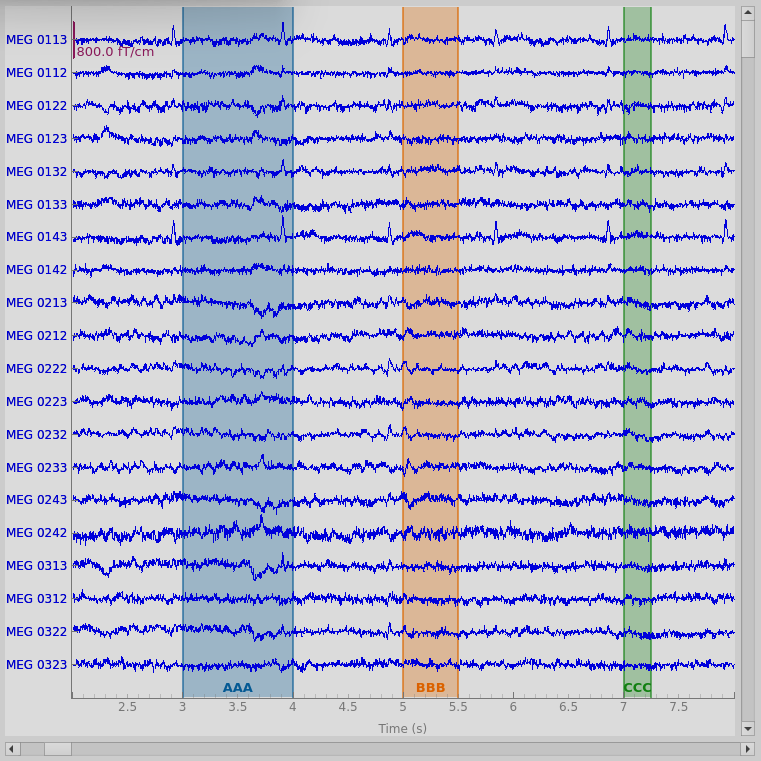
三个注释显示为不同颜色的矩形,因为它们具有不同的description值。还请注意,在绘图窗口底部的小滚动条中出现了彩色的span,这使您可以轻松地快速查看注释在raw中的位置,以便您可以轻松浏览数据以查找和检查它们。
交互式地添加注释
也可以通过在绘图窗口中点击并拖动鼠标,以交互方式向raw对象添加注释。要做到这一点,您必须首先进入“注释模式”,在绘图窗口聚焦时按a,这将打开注解控件:
1 | fig = raw.plot(start=2, duration=6) |
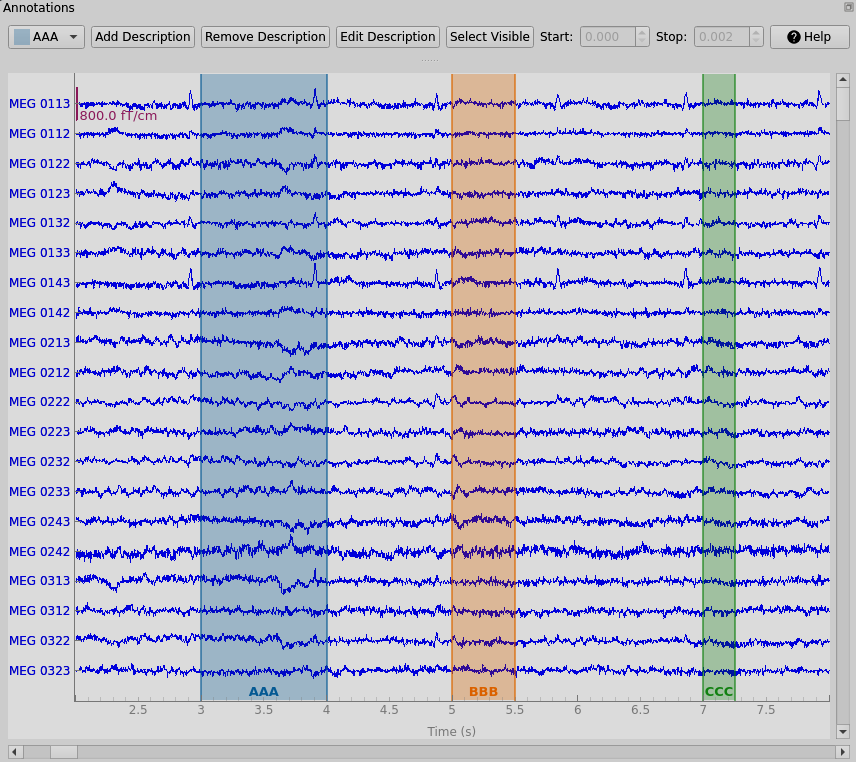
左边的下拉菜单决定了主绘图窗口中的下一次点击-拖动操作将创建哪些现有的标签。点击添加描述按钮,可以添加新的注释描述;新的描述将被添加到描述列表中并自动选择。下拉菜单中有以下功能:通过删除描述,可以删除包括注释在内的描述。使用编辑描述,您可以仅编辑当前选中的描述,也可以编辑描述的所有注释。通过设置可见,您可以显示或隐藏描述。
在交互式注释期间,还可以通过单击并拖动与该注释对应的突出显示矩形的左边缘或右边缘来调整注释的开始和结束时间。当一个注释被选中时,start和stop的值在两个框中可见,也可以在那里编辑。
注意,调用set_annotations()会替换当前存储在raw对象中的任何注释,因此在使用交互式创建的注释时要小心,如果不小心覆盖交互式注释,可能会损失很多工作。一个很好的保护措施是在您完成交互式注释会话之后运行interactive_annot = raw.annotations,以便将注释存储在raw对象之外的单独变量中。
在预处理和分析之后,注释会咋样?
你可能已经注意到,注释控件窗口中新标签的描述默认为BAD_。原因是注释通常用于标记错误时间跨度的数据,例如不能通过投影或滤波等其他方式消除的运动伪影或环境干扰。一些MNE-Python操作是“注释感知的”,并将避免使用以“bad”或“bad”开头的描述注释的数据。这种操作通常有一个布尔参数reject_by_annotation。这些操作的例子包括独立成分分析(mne.preprocessing.ICA)、查找心跳和眨眼工件的函数(find_ecg_events()、find_eog_events())以及从连续数据中创建epoched数据(mne.Epochs)。
注释对象相关的操作
只要注释对象共享同一个orig_time,就可以简单地用+操作符将它们相加:
1 | new_annot = mne.Annotations(onset=3.75, duration=0.75, description="AAA") |
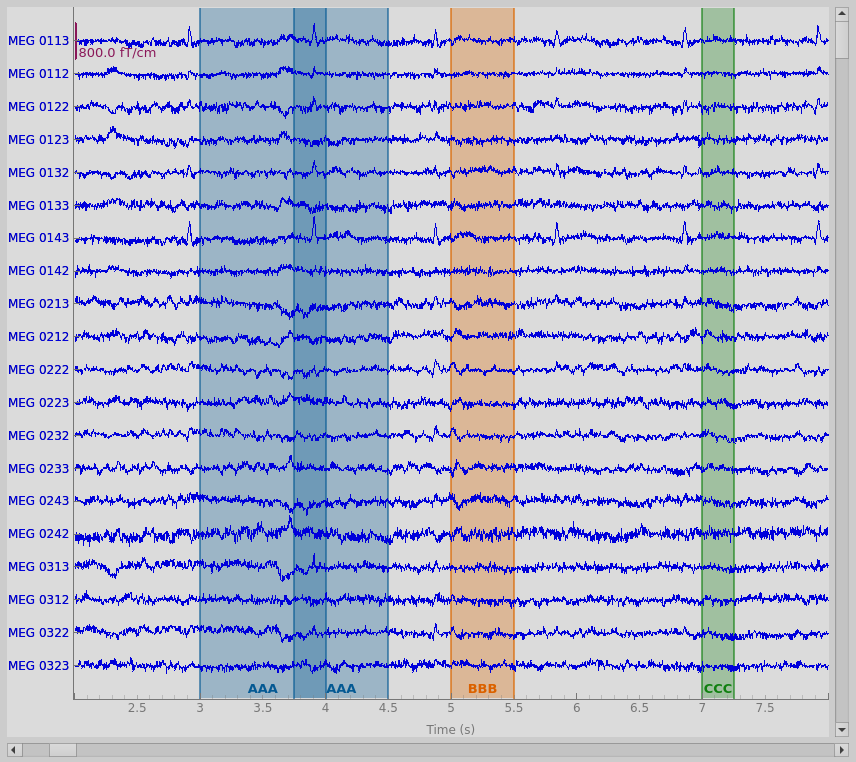
请注意,可以创建重叠注释,即使它们共享相同的描述。这在交互式注释时是不可能的。单击并拖动以创建与具有相同描述的现有注释重叠的新注释,将导致新旧注释合并。
可以通过索引annotations对象来访问单个注释,而注释的子集可以通过切片或使用列表、元组或索引数组来实现:
1 | print(raw.annotations[0]) # just the first annotation |
OrderedDict([(‘onset’, 45.95597082905339), (‘duration’, 1.0), (‘description’, ‘AAA’), (‘orig_time’, datetime.datetime(2002, 12, 3, 19, 1, 10, 720100, tzinfo=datetime.timezone.utc))])
<Annotations | 2 segments: AAA (2)>
<Annotations | 2 segments: BBB (1), CCC (1)>
你也可以在annotations对象中迭代注释:
1 | for ann in raw.annotations: |
‘AAA’ goes from 45.95597082905339 to 46.95597082905339
‘AAA’ goes from 46.70597082905339 to 47.45597082905339
‘BBB’ goes from 47.95597082905339 to 48.45597082905339
‘CCC’ goes from 49.95597082905339 to 50.20597082905339
请注意,迭代、索引和切片注释都返回一个副本,因此对索引、切片或迭代元素的更改不会修改原始注释对象。
1 | # later_annot WILL be changed, because we're modifying the first element of |
99.0
从文件读取和写入注释
注解对象有一个save()方法,可以写入.fif、.csv和.txt格式,写入的格式根据你提供的文件名中的文件扩展名推断。请注意,写入文件的起始信息的格式依赖于文件扩展名。.csv文件以时间戳的形式存储起始点,而.txt文件写入浮点数,以秒为单位。有一个对应的read_annotations()函数可以从磁盘加载它们:
1 | raw.annotations.save("saved-annotations.csv", overwrite=True) |
<Annotations | 4 segments: AAA (2), BBB (1), CCC (1)>




